This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/Total-Resort-3120 on 2024-10-24 11:21:53+00:00.
Intro:
If you haven't seen it yet, there's a new model called Mochi 1 that displays incredible video capabilities, and the good news for us is that it's local and has an Apache 2.0 licence: https://x.com/genmoai/status/1848762405779574990
Our overloard kijai made a ComfyUi node that makes this feat possible in the first place, here's how it works:
- The text encoder t5xxl is loaded (~9gb vram) to encode your prompt, then it's unloads.
- Mochi 1 gets loaded, you can choose between fp8 (up to 361 frames before memory overflow -> 15 sec (24fps)) or bf16 (up to 61 frames before overflow -> 2.5 seconds (24fps)), then it unloads
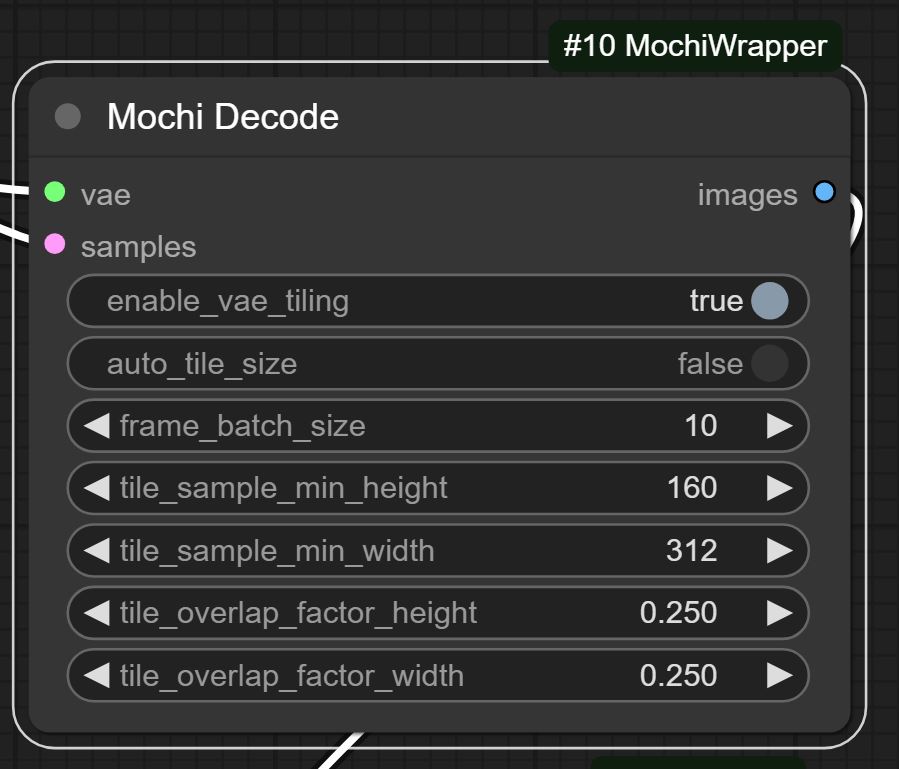
- The VAE will transform the result into a video, this is the part that asks for way more than simply 24gb of VRAM. Fortunatly for us we have a technique called vae_tilting that'll make the calculations bit by bit so that it won't overflow our 24gb VRAM card. You don't need to tinker with those values, he made a workflow for it and it just works.
How to install:
1) Go to the ComfyUI_windows_portable\ComfyUI\custom_nodes folder, open cmd and type this command:
git clone https://github.com/kijai/ComfyUI-MochiWrapper
2) Go to the ComfyUI_windows_portable\update folder, open cmd and type those 2 commands:
..\python_embeded\python.exe -s -m pip install accelerate
..\python_embeded\python.exe -s -m pip install einops
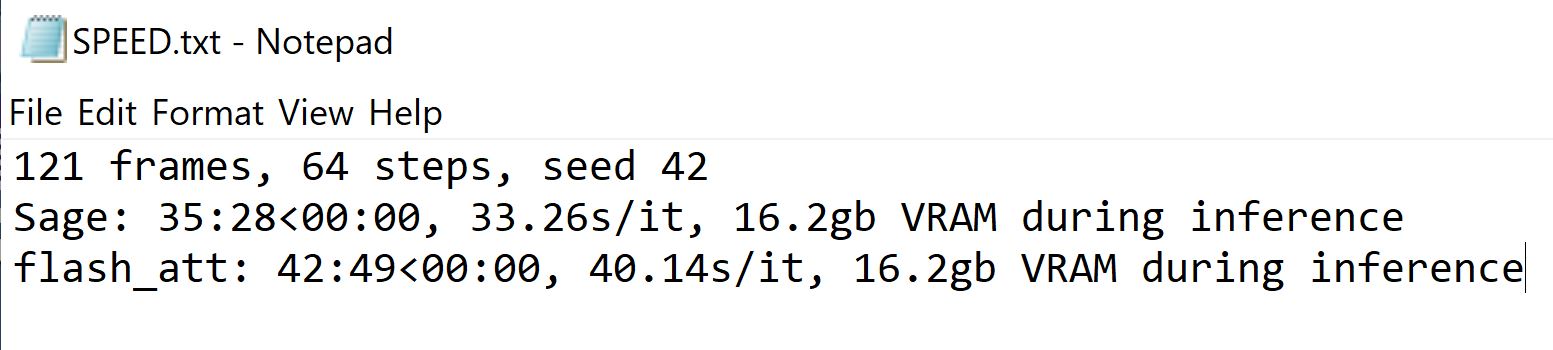
3) You have 3 optimization choices when running this model, sdpa, flash_attn and sage_attn
sage_attn is the fastest of the 3, so only this one will matter there.
Go to the ComfyUI_windows_portable\update folder, open cmd and type this command:
..\python_embeded\python.exe -s -m pip install sageattention
4) To use sage_attn you need triton, for windows it's quite tricky to install but it's definitely possible:
- I highly suggest you to have torch 2.5.0 + cuda 12.4 to keep things running smoothly, if you're not sure you have it, go to the ComfyUI_windows_portable\update folder, open cmd and type this command:
..\python_embeded\python.exe -s -m pip install --upgrade torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
-
Once you've done that, go to this link: , download the triton-3.1.0-cp311-cp311-win_amd64.whl binary and put it on the ComfyUI_windows_portable\update folder
-
Go to the ComfyUI_windows_portable\update folder, open cmd and type this command:
..\python_embeded\python.exe -s -m pip install triton-3.1.0-cp311-cp311-win_amd64.whl
5) Triton still won't work if we don't do this:
-
Install python 3.11.9 on your computer
-
Go to C:\Users\Home\AppData\Local\Programs\Python\Python311 and copy the libs and include folders
-
Paste those folders onto ComfyUI_windows_portable\python_embeded
Triton and sage attention should be working now.
6) Download the fp8 or the bf16 model
-
Go to ComfyUI_windows_portable\ComfyUI\models and create a folder named "diffusion_models"
-
Go to ComfyUI_windows_portable\ComfyUI\models\diffusion_models, create a folder named "mochi" and put your model in there.
7) Download the VAE
- Go to ComfyUI_windows_portable\ComfyUI\models\vae, create a folder named "mochi" and put your VAE in there
8) Download the text encoder
- Go to ComfyUI_windows_portable\ComfyUI\models\clip, and put your text encoder in there.
And there you have it, now that everything is settled in, load this workflow on ComfyUi and you can make your own AI videos, have fun!
A 22 years old woman dancing in a Hotel Room, she is holding a Pikachu plush





{kind=link}
{kind=link}
{kind=link}
![Flux.1 [dev]](https://preview.redd.it/3454259g1iwd1.png?width=1024&format=png&auto=webp&s=dadd2b6f89a54d233e3d3544fc78a9f1df530716){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}