That's the rule for astronomy. If it happens once, it always happens; we just haven't seen it yet
MaxHardwood
joined 2 years ago
You're using the term faith differently than everybody else.
BoTh SiDeS!!
They are not the same. One is an open Nazi party
Almost 50% of energy is lost in transmission. Keeping renewable energy closer is good.
How do you think power/energy is sent to your home?
"Sport"
What are you on about? Everybody who isn't an embarrassed-temporarily-broke-millionaire wants this
Gosh darn fuck I'm annoyed by how stupid your comment is.
Golf: 20 acres for 3 people
Soccer: 50 meters for 10+
How do you live being this fucking ignorant?
What the fuck did I do?!?
It claims to have a Dimensity 9000 SoC and if you include 12GB of RAM this seems pretty powerful for a very inexpensive price. I can't find any reviews on it though.
Any thoughts?
Edit: Not sure why the Aliexpress link doesn't work but here's the screenshot and specs
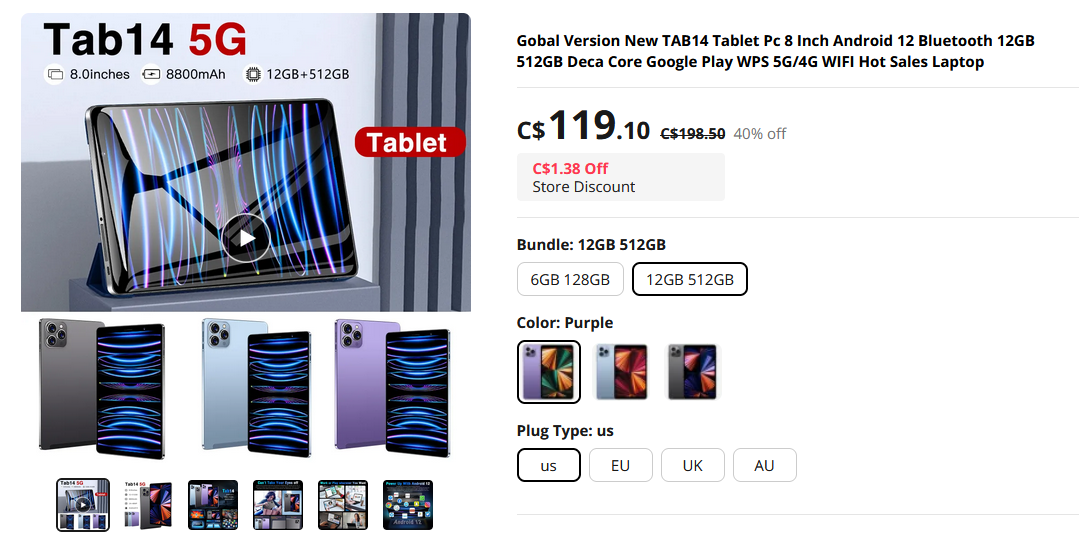
Model No.: Tab14
CPU: Dimensity 9000 Deca Core (Latest 10 Core)
SIM/TF: 2 SIM Card Slots (Nano SIM) + 1 TF Card Slots (Maximum support extension 128GB)
Screen: 8.0 Inch 4K Screen
Resolution :2560*1600
Camera: Front Camera 24MP+ Rear Camera 48MP
Memory: 12GB RAM+512GB ROM/6GB RAM+128GB ROM
System: Android 12 System
Battery: 8800mAh High Density Lithium-ion battery
Unique Back Cover: Hot Bend 3D Plating Gradient Glass Back Cover. It is art, it is also technology!
Net-Work: GSM850/900/1800/1900MHz, 3G: WCDMA850/1900/2100MHz, 4G,5G
Vibration:Support
Multi Media: MP3/MP4/3GP/FM Radio/Bluetooth
Multi Function: Full screen, Face recognition,Screen finger print, Dual SIM, Wifi, GPS, Gravity Sensor, Alarm ,
Calendar,Calculator,Audio recorder ,Video recorder, WAP/MMS/GPR, Image viewer,E-Book,World clock
Languages: Multi-language support
Seems super sus...
view more: next ›
Absolutely. They're nothing alike.