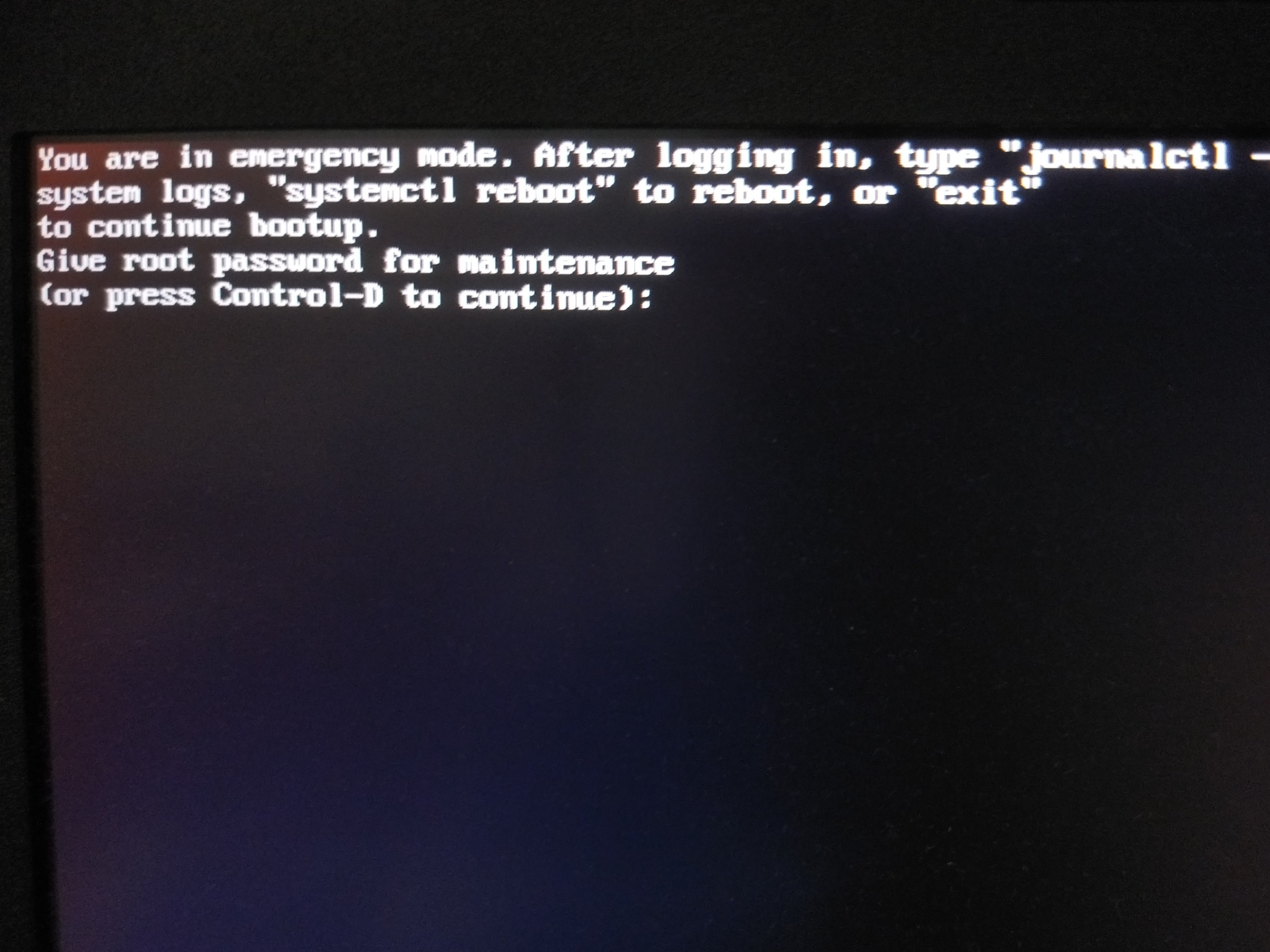
Hello,
I have an issue with btrfs I can't really make heads or tails of. I thought I'd try lemmy even if the community is small here (I refuse to go back to the hard-R place).
Recently, my machine seemingly froze, after which I force reset. After booting back up, the journal shows that the scrub failed for the last boot. One interesting note was the tty1 console showed that the kernel had a SIGILL(?), but I didnt catch it, as switching vts one more time froze the machine completely after switching back to X.
Kernel:
Archlinux Linux novo 6.6.8-arch1-1 #1 SMP PREEMPT_DYNAMIC Thu, 21 Dec 2023 19:01:01 +0000 x86_64 GNU/Linux
I only have a vague idea of what chunk maps are and I have no idea on how to figure out if I lost data.
Running btrfs inspect-internal logical-resolve / gives ENOENT for any of the unfound chunk map logicals in the output.
Any help highly appreciated :)
The dmesg output is following:
Jan 02 02:21:19 novo.vcpu kernel: BTRFS info (device nvme0n1p4): balance: start -dusage=30 -musage=30 -susage=30
Jan 02 02:21:19 novo.vcpu kernel: BTRFS info (device nvme0n1p4): relocating block group 2327056482304 flags system
Jan 02 02:21:19 novo.vcpu kernel: BTRFS info (device nvme0n1p4): found 5 extents, stage: move data extents
Jan 02 02:21:19 novo.vcpu kernel: BTRFS info (device nvme0n1p4): scrub: started on devid 1
Jan 02 02:21:19 novo.vcpu kernel: BTRFS info (device nvme0n1p4): balance: ended with status: 0
Jan 02 02:21:19 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173215744 length 4096
Jan 02 02:21:19 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173215744 length 61440
Jan 02 02:21:19 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173215744 length 4096
Jan 02 02:21:19 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173215744 length 4096
Jan 02 02:21:19 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173219840 length 4096
Jan 02 02:21:19 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173219840 length 4096
Jan 02 02:21:19 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173223936 length 4096
Jan 02 02:21:19 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173223936 length 4096
Jan 02 02:21:19 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173228032 length 4096
Jan 02 02:21:19 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173228032 length 4096
Jan 02 02:21:19 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173232128 length 4096
Jan 02 02:21:19 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173232128 length 4096
Jan 02 02:21:19 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173236224 length 4096
Jan 02 02:21:19 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173236224 length 4096
Jan 02 02:21:19 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173240320 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173240320 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173244416 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173244416 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173248512 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173248512 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173252608 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173252608 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173256704 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173256704 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173260800 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173260800 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173264896 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173264896 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173268992 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173268992 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173273088 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 173273088 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS error (device nvme0n1p4): fixed up error at logical 173211648 on dev /dev/nvme0n1p4 physical 173211648
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 2297397248 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 2297397248 length 32768
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 2297397248 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 2297397248 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 2297401344 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 2297401344 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 2297405440 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 2297405440 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 2297409536 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 2297409536 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 2297413632 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 2297413632 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 2297417728 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 2297417728 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 2297421824 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 2297421824 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 2297425920 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 2297425920 length 4096
Jan 02 02:21:20 novo.vcpu kernel: BTRFS error (device nvme0n1p4): fixed up error at logical 2297364480 on dev /dev/nvme0n1p4 physical 2297364480
Jan 02 02:21:20 novo.vcpu kernel: BTRFS error (device nvme0n1p4): fixed up error at logical 2297364480 on dev /dev/nvme0n1p4 physical 2297364480
Jan 02 02:21:20 novo.vcpu kernel: BTRFS error (device nvme0n1p4): fixed up error at logical 2297364480 on dev /dev/nvme0n1p4 physical 2297364480
Jan 02 02:21:20 novo.vcpu kernel: BTRFS error (device nvme0n1p4): fixed up error at logical 2297364480 on dev /dev/nvme0n1p4 physical 2297364480
Jan 02 02:21:20 novo.vcpu kernel: BTRFS error (device nvme0n1p4): fixed up error at logical 2297364480 on dev /dev/nvme0n1p4 physical 2297364480
Jan 02 02:21:20 novo.vcpu kernel: BTRFS error (device nvme0n1p4): fixed up error at logical 2297364480 on dev /dev/nvme0n1p4 physical 2297364480
Jan 02 02:21:20 novo.vcpu kernel: BTRFS error (device nvme0n1p4): fixed up error at logical 2297364480 on dev /dev/nvme0n1p4 physical 2297364480
Jan 02 02:21:20 novo.vcpu kernel: BTRFS error (device nvme0n1p4): fixed up error at logical 2297364480 on dev /dev/nvme0n1p4 physical 2297364480
Jan 02 02:21:21 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 4453298176 length 4096
Jan 02 02:21:21 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 4453298176 length 4096
Jan 02 02:21:21 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 4453298176 length 4096
Jan 02 02:21:21 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 4453298176 length 4096
Jan 02 02:21:21 novo.vcpu kernel: BTRFS error (device nvme0n1p4): fixed up error at logical 4453236736 on dev /dev/nvme0n1p4 physical 4453236736
Jan 02 02:21:22 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 6618599424 length 4096
Jan 02 02:21:22 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 6618599424 length 12288
Jan 02 02:21:22 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 6618599424 length 4096
Jan 02 02:21:22 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 6618599424 length 4096
Jan 02 02:21:22 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 6618603520 length 4096
Jan 02 02:21:22 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 6618603520 length 4096
Jan 02 02:21:22 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 6618607616 length 4096
Jan 02 02:21:22 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 6618607616 length 4096
Jan 02 02:21:23 novo.vcpu kernel: kauditd_printk_skb: 9 callbacks suppressed
Jan 02 02:21:23 novo.vcpu kernel: audit: type=1100 audit(1704154883.589:1799): pid=555000 uid=1000 auid=1000 ses=1 msg='op=PAM:unix_chkpwd acct="vytautas" exe="/usr/bin/unix_chkpwd" hostname=? addr=? terminal=? res=success'
Jan 02 02:21:23 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 8749236224 length 4096
Jan 02 02:21:23 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 8749236224 length 16384
Jan 02 02:21:23 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 8749236224 length 4096
Jan 02 02:21:23 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 8749236224 length 4096
Jan 02 02:21:23 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 8749240320 length 4096
Jan 02 02:21:23 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 8749240320 length 4096
Jan 02 02:21:23 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 8749244416 length 4096
Jan 02 02:21:23 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 8749244416 length 4096
Jan 02 02:21:23 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 8749248512 length 4096
Jan 02 02:21:23 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 8749248512 length 4096
Jan 02 02:21:24 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 10910683136 length 4096
Jan 02 02:21:24 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 10910683136 length 12288
Jan 02 02:21:24 novo.vcpu kernel: ------------[ cut here ]------------
Jan 02 02:21:24 novo.vcpu kernel: kernel BUG at include/linux/scatterlist.h:115!
Jan 02 02:21:24 novo.vcpu kernel: invalid opcode: 0000 [#1] PREEMPT SMP NOPTI
Jan 02 02:21:24 novo.vcpu kernel: CPU: 6 PID: 554890 Comm: btrfs Tainted: P OE 6.6.8-arch1-1 #1 2ffcc416f976199fcae9446e8159d64f5aa7b1db
Jan 02 02:21:24 novo.vcpu kernel: Hardware name: LENOVO 81Q9/LNVNB161216, BIOS AUCN61WW 04/19/2022
Jan 02 02:21:24 novo.vcpu kernel: RIP: 0010:__blk_rq_map_sg+0x4dc/0x4f0
Jan 02 02:21:24 novo.vcpu kernel: Code: 24 4c 8b 4c 24 08 84 c0 4c 8b 5c 24 10 44 8b 44 24 18 49 8b 07 0f 84 fd fb ff ff 4c 8b 54 24 30 48 8b 54 24 38 e9 34 ff ff ff <0f> 0b 0f 0b e8 3b d8 7d 00 66 66 2e 0f 1f 84 00 00 00 00 00 90 90
Jan 02 02:21:24 novo.vcpu kernel: RSP: 0000:ffffc9000680b858 EFLAGS: 00010202
Jan 02 02:21:24 novo.vcpu kernel: RAX: ffff888169d5f300 RBX: 0000000000000000 RCX: d94b4edc3cf35329
Jan 02 02:21:24 novo.vcpu kernel: RDX: 0000000000000000 RSI: 0000000000000000 RDI: ffff888169d5f300
Jan 02 02:21:24 novo.vcpu kernel: RBP: 00000002b45f0000 R08: 0000000000000000 R09: 0000000000000080
Jan 02 02:21:24 novo.vcpu kernel: R10: ffff8881d18886f0 R11: ffff888111586900 R12: 0000000000001000
Jan 02 02:21:24 novo.vcpu kernel: R13: 0000000000005000 R14: ffff8881d18886f0 R15: ffffc9000680b930
Jan 02 02:21:24 novo.vcpu kernel: FS: 00007fad5b87a6c0(0000) GS:ffff88848ad80000(0000) knlGS:0000000000000000
Jan 02 02:21:24 novo.vcpu kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
Jan 02 02:21:24 novo.vcpu kernel: CR2: 000055c11731ed60 CR3: 0000000043c4c003 CR4: 0000000000770ee0
Jan 02 02:21:24 novo.vcpu kernel: PKRU: 55555554
Jan 02 02:21:24 novo.vcpu kernel: Call Trace:
Jan 02 02:21:24 novo.vcpu kernel:
Jan 02 02:21:24 novo.vcpu kernel: ? die+0x36/0x90
Jan 02 02:21:24 novo.vcpu kernel: ? do_trap+0xda/0x100
Jan 02 02:21:24 novo.vcpu kernel: ? __blk_rq_map_sg+0x4dc/0x4f0
Jan 02 02:21:24 novo.vcpu kernel: ? do_error_trap+0x6a/0x90
Jan 02 02:21:24 novo.vcpu kernel: ? __blk_rq_map_sg+0x4dc/0x4f0
Jan 02 02:21:24 novo.vcpu kernel: ? exc_invalid_op+0x50/0x70
Jan 02 02:21:24 novo.vcpu kernel: ? __blk_rq_map_sg+0x4dc/0x4f0
Jan 02 02:21:24 novo.vcpu kernel: ? asm_exc_invalid_op+0x1a/0x20
Jan 02 02:21:24 novo.vcpu kernel: ? __blk_rq_map_sg+0x4dc/0x4f0
Jan 02 02:21:24 novo.vcpu kernel: ? __blk_rq_map_sg+0x102/0x4f0
Jan 02 02:21:24 novo.vcpu kernel: ? mempool_alloc+0x86/0x1b0
Jan 02 02:21:24 novo.vcpu kernel: nvme_prep_rq.part.0+0xad/0x840 [nvme 0902d60a773d6eac1c90b6dbf9fb606c9432cc33]
Jan 02 02:21:24 novo.vcpu kernel: ? try_to_wake_up+0x2b7/0x640
Jan 02 02:21:24 novo.vcpu kernel: nvme_queue_rqs+0xc0/0x290 [nvme 0902d60a773d6eac1c90b6dbf9fb606c9432cc33]
Jan 02 02:21:24 novo.vcpu kernel: blk_mq_flush_plug_list.part.0+0x58f/0x5c0
Jan 02 02:21:24 novo.vcpu kernel: ? queue_work_on+0x3b/0x50
Jan 02 02:21:24 novo.vcpu kernel: ? btrfs_submit_chunk+0x3ae/0x520 [btrfs e817a81ee371f312ac9558f8778b637a23a2adc5]
Jan 02 02:21:24 novo.vcpu kernel: __blk_flush_plug+0xf5/0x150
Jan 02 02:21:24 novo.vcpu kernel: blk_finish_plug+0x29/0x40
Jan 02 02:21:24 novo.vcpu kernel: submit_initial_group_read+0xa3/0x1b0 [btrfs e817a81ee371f312ac9558f8778b637a23a2adc5]
Jan 02 02:21:24 novo.vcpu kernel: flush_scrub_stripes+0x219/0x260 [btrfs e817a81ee371f312ac9558f8778b637a23a2adc5]
Jan 02 02:21:24 novo.vcpu kernel: scrub_stripe+0x53c/0x700 [btrfs e817a81ee371f312ac9558f8778b637a23a2adc5]
Jan 02 02:21:24 novo.vcpu kernel: scrub_chunk+0xcb/0x130 [btrfs e817a81ee371f312ac9558f8778b637a23a2adc5]
Jan 02 02:21:24 novo.vcpu kernel: scrub_enumerate_chunks+0x2f0/0x6c0 [btrfs e817a81ee371f312ac9558f8778b637a23a2adc5]
Jan 02 02:21:24 novo.vcpu kernel: btrfs_scrub_dev+0x212/0x610 [btrfs e817a81ee371f312ac9558f8778b637a23a2adc5]
Jan 02 02:21:24 novo.vcpu kernel: btrfs_ioctl+0x2d0/0x2640 [btrfs e817a81ee371f312ac9558f8778b637a23a2adc5]
Jan 02 02:21:24 novo.vcpu kernel: ? folio_add_new_anon_rmap+0x45/0xe0
Jan 02 02:21:24 novo.vcpu kernel: ? set_ptes.isra.0+0x1e/0xa0
Jan 02 02:21:24 novo.vcpu kernel: ? cap_safe_nice+0x38/0x70
Jan 02 02:21:24 novo.vcpu kernel: ? security_task_setioprio+0x33/0x50
Jan 02 02:21:24 novo.vcpu kernel: ? set_task_ioprio+0xa7/0x130
Jan 02 02:21:24 novo.vcpu kernel: __x64_sys_ioctl+0x94/0xd0
Jan 02 02:21:24 novo.vcpu kernel: do_syscall_64+0x5d/0x90
Jan 02 02:21:24 novo.vcpu kernel: ? __count_memcg_events+0x42/0x90
Jan 02 02:21:24 novo.vcpu kernel: ? count_memcg_events.constprop.0+0x1a/0x30
Jan 02 02:21:24 novo.vcpu kernel: ? handle_mm_fault+0xa2/0x360
Jan 02 02:21:24 novo.vcpu kernel: ? do_user_addr_fault+0x30f/0x660
Jan 02 02:21:24 novo.vcpu kernel: ? exc_page_fault+0x7f/0x180
Jan 02 02:21:24 novo.vcpu kernel: entry_SYSCALL_64_after_hwframe+0x6e/0xd8
Jan 02 02:21:24 novo.vcpu kernel: RIP: 0033:0x7fad5b9e33af
Jan 02 02:21:24 novo.vcpu kernel: Code: 00 48 89 44 24 18 31 c0 48 8d 44 24 60 c7 04 24 10 00 00 00 48 89 44 24 08 48 8d 44 24 20 48 89 44 24 10 b8 10 00 00 00 0f 05 <89> c2 3d 00 f0 ff ff 77 18 48 8b 44 24 18 64 48 2b 04 25 28 00 00
Jan 02 02:21:24 novo.vcpu kernel: RSP: 002b:00007fad5b879c80 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
Jan 02 02:21:24 novo.vcpu kernel: RAX: ffffffffffffffda RBX: 0000562c0a109450 RCX: 00007fad5b9e33af
Jan 02 02:21:24 novo.vcpu kernel: RDX: 0000562c0a109450 RSI: 00000000c400941b RDI: 0000000000000003
Jan 02 02:21:24 novo.vcpu kernel: RBP: 0000000000000000 R08: 00007fad5b87a6c0 R09: 0000000000000000
Jan 02 02:21:24 novo.vcpu kernel: R10: 0000000000000000 R11: 0000000000000246 R12: fffffffffffffdb8
Jan 02 02:21:24 novo.vcpu kernel: R13: 0000000000000000 R14: 00007ffe13568550 R15: 00007fad5b07a000
Jan 02 02:21:24 novo.vcpu kernel:
Jan 02 02:21:24 novo.vcpu kernel: Modules linked in: cdc_acm uinput udp_diag tcp_diag inet_diag exfat uas usb_storage uhid snd_usb_audio snd_usbmidi_lib snd_ump snd_rawmidi r8153_ecm cdc_ether usbnet r8152 mii xt_nat xt_tcpudp veth xt_conntrack xt_MASQUERADE nf_conntrack_netlink iptable_nat xt_addrtype iptable_filter br_netfilter ccm rfcomm snd_seq_dummy snd_hrtimer snd_seq snd_seq_device nft_reject_ipv4 nf_reject_ipv4 nft_reject nft_ct nft_masq nft_chain_nat nf_tables nf_nat_h323 nf_conntrack_h323 evdi(OE) nf_nat_pptp nf_conntrack_pptp nf_nat_tftp nf_conntrack_tftp nf_nat_sip nf_conntrack_sip nf_nat_irc nf_conntrack_irc nf_nat_ftp overlay nf_conntrack_ftp nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 wireguard curve25519_x86_64 libchacha20poly1305 chacha_x86_64 poly1305_x86_64 libcurve25519_generic libchacha ip6_udp_tunnel udp_tunnel bridge stp llc cmac algif_hash algif_skcipher af_alg bnep snd_ctl_led snd_soc_skl_hda_dsp snd_soc_intel_hda_dsp_common snd_soc_hdac_hdmi snd_sof_probes snd_hda_codec_hdmi snd_hda_codec_realtek
Jan 02 02:21:24 novo.vcpu kernel: snd_hda_codec_generic ledtrig_audio snd_soc_dmic snd_sof_pci_intel_icl snd_sof_intel_hda_common soundwire_intel snd_sof_intel_hda_mlink soundwire_cadence snd_sof_intel_hda intel_tcc_cooling snd_sof_pci snd_sof_xtensa_dsp x86_pkg_temp_thermal intel_powerclamp snd_sof hid_sensor_accel_3d coretemp hid_sensor_trigger snd_sof_utils industrialio_triggered_buffer kvm_intel snd_soc_hdac_hda kfifo_buf snd_hda_ext_core hid_sensor_iio_common industrialio hid_sensor_custom snd_soc_acpi_intel_match snd_soc_acpi kvm snd_intel_dspcfg hid_sensor_hub snd_intel_sdw_acpi snd_hda_codec irqbypass uvcvideo crct10dif_pclmul snd_hda_core btusb joydev intel_ishtp_hid polyval_clmulni videobuf2_vmalloc snd_hwdep btrtl yoga_usage_mode(OE) mousedev uvc vboxnetflt(OE) polyval_generic vboxnetadp(OE) btintel soundwire_generic_allocation videobuf2_memops soundwire_bus gf128mul videobuf2_v4l2 btbcm i915 btmtk snd_soc_core ghash_clmulni_intel wacom vboxdrv(OE) videodev snd_compress hid_multitouch sha1_ssse3 usbhid bluetooth iTCO_wdt iwlmvm
Jan 02 02:21:24 novo.vcpu kernel: videobuf2_common rapl drm_buddy ac97_bus intel_pmc_bxt ecdh_generic crc16 mc iTCO_vendor_support mei_pxp mei_hdcp intel_rapl_msr intel_cstate processor_thermal_device_pci_legacy mac80211 snd_pcm_dmaengine i2c_algo_bit spi_nor processor_thermal_device think_lmi libarc4 intel_uncore firmware_attributes_class iwlwifi processor_thermal_rfim mtd ttm pcspkr snd_pcm wmi_bmof processor_thermal_mbox i2c_i801 snd_timer i2c_smbus processor_thermal_rapl intel_ish_ipc drm_display_helper ucsi_acpi snd lenovo_ymc cec intel_lpss_pci soundcore intel_wmi_thunderbolt thunderbolt intel_ishtp mei_me intel_rapl_common cfg80211 typec_ucsi int340x_thermal_zone mei typec intel_lpss intel_gtt vfat idma64 roles intel_soc_dts_iosf i2c_hid_acpi fat i2c_hid ideapad_laptop sparse_keymap platform_profile rfkill soc_button_array int3400_thermal acpi_thermal_rel acpi_pad acpi_tad mac_hid i2c_dev coda sg crypto_user acpi_call(OE) fuse dm_mod loop nfnetlink ip_tables x_tables btrfs blake2b_generic xor raid6_pq libcrc32c crc32c_generic
Jan 02 02:21:24 novo.vcpu kernel: crc32_pclmul crc32c_intel serio_raw sha512_ssse3 atkbd sha256_ssse3 libps2 aesni_intel vivaldi_fmap nvme crypto_simd cryptd nvme_core spi_intel_pci xhci_pci spi_intel nvme_common xhci_pci_renesas video i8042 wmi serio
Jan 02 02:21:24 novo.vcpu kernel: Unloaded tainted modules: nvidia(POE):1
Jan 02 02:21:24 novo.vcpu kernel: ---[ end trace 0000000000000000 ]---
Jan 02 02:21:24 novo.vcpu kernel: RIP: 0010:__blk_rq_map_sg+0x4dc/0x4f0
Jan 02 02:21:24 novo.vcpu kernel: Code: 24 4c 8b 4c 24 08 84 c0 4c 8b 5c 24 10 44 8b 44 24 18 49 8b 07 0f 84 fd fb ff ff 4c 8b 54 24 30 48 8b 54 24 38 e9 34 ff ff ff <0f> 0b 0f 0b e8 3b d8 7d 00 66 66 2e 0f 1f 84 00 00 00 00 00 90 90
Jan 02 02:21:24 novo.vcpu kernel: RSP: 0000:ffffc9000680b858 EFLAGS: 00010202
Jan 02 02:21:24 novo.vcpu kernel: RAX: ffff888169d5f300 RBX: 0000000000000000 RCX: d94b4edc3cf35329
Jan 02 02:21:24 novo.vcpu kernel: RDX: 0000000000000000 RSI: 0000000000000000 RDI: ffff888169d5f300
Jan 02 02:21:24 novo.vcpu kernel: RBP: 00000002b45f0000 R08: 0000000000000000 R09: 0000000000000080
Jan 02 02:21:24 novo.vcpu kernel: R10: ffff8881d18886f0 R11: ffff888111586900 R12: 0000000000001000
Jan 02 02:21:24 novo.vcpu kernel: R13: 0000000000005000 R14: ffff8881d18886f0 R15: ffffc9000680b930
Jan 02 02:21:24 novo.vcpu kernel: FS: 00007fad5b87a6c0(0000) GS:ffff88848ad80000(0000) knlGS:0000000000000000
Jan 02 02:21:24 novo.vcpu kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
Jan 02 02:21:24 novo.vcpu kernel: CR2: 000055c11731ed60 CR3: 0000000043c4c003 CR4: 0000000000770ee0
Jan 02 02:21:24 novo.vcpu kernel: PKRU: 55555554
Jan 02 02:21:24 novo.vcpu kernel: ------------[ cut here ]------------
Jan 02 02:21:24 novo.vcpu kernel: WARNING: CPU: 6 PID: 554890 at kernel/exit.c:818 do_exit+0x8e9/0xb20
Jan 02 02:21:24 novo.vcpu kernel: Modules linked in: cdc_acm uinput udp_diag tcp_diag inet_diag exfat uas usb_storage uhid snd_usb_audio snd_usbmidi_lib snd_ump snd_rawmidi r8153_ecm cdc_ether usbnet r8152 mii xt_nat xt_tcpudp veth xt_conntrack xt_MASQUERADE nf_conntrack_netlink iptable_nat xt_addrtype iptable_filter br_netfilter ccm rfcomm snd_seq_dummy snd_hrtimer snd_seq snd_seq_device nft_reject_ipv4 nf_reject_ipv4 nft_reject nft_ct nft_masq nft_chain_nat nf_tables nf_nat_h323 nf_conntrack_h323 evdi(OE) nf_nat_pptp nf_conntrack_pptp nf_nat_tftp nf_conntrack_tftp nf_nat_sip nf_conntrack_sip nf_nat_irc nf_conntrack_irc nf_nat_ftp overlay nf_conntrack_ftp nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 wireguard curve25519_x86_64 libchacha20poly1305 chacha_x86_64 poly1305_x86_64 libcurve25519_generic libchacha ip6_udp_tunnel udp_tunnel bridge stp llc cmac algif_hash algif_skcipher af_alg bnep snd_ctl_led snd_soc_skl_hda_dsp snd_soc_intel_hda_dsp_common snd_soc_hdac_hdmi snd_sof_probes snd_hda_codec_hdmi snd_hda_codec_realtek
Jan 02 02:21:24 novo.vcpu kernel: snd_hda_codec_generic ledtrig_audio snd_soc_dmic snd_sof_pci_intel_icl snd_sof_intel_hda_common soundwire_intel snd_sof_intel_hda_mlink soundwire_cadence snd_sof_intel_hda intel_tcc_cooling snd_sof_pci snd_sof_xtensa_dsp x86_pkg_temp_thermal intel_powerclamp snd_sof hid_sensor_accel_3d coretemp hid_sensor_trigger snd_sof_utils industrialio_triggered_buffer kvm_intel snd_soc_hdac_hda kfifo_buf snd_hda_ext_core hid_sensor_iio_common industrialio hid_sensor_custom snd_soc_acpi_intel_match snd_soc_acpi kvm snd_intel_dspcfg hid_sensor_hub snd_intel_sdw_acpi snd_hda_codec irqbypass uvcvideo crct10dif_pclmul snd_hda_core btusb joydev intel_ishtp_hid polyval_clmulni videobuf2_vmalloc snd_hwdep btrtl yoga_usage_mode(OE) mousedev uvc vboxnetflt(OE) polyval_generic vboxnetadp(OE) btintel soundwire_generic_allocation videobuf2_memops soundwire_bus gf128mul videobuf2_v4l2 btbcm i915 btmtk snd_soc_core ghash_clmulni_intel wacom vboxdrv(OE) videodev snd_compress hid_multitouch sha1_ssse3 usbhid bluetooth iTCO_wdt iwlmvm
Jan 02 02:21:24 novo.vcpu kernel: videobuf2_common rapl drm_buddy ac97_bus intel_pmc_bxt ecdh_generic crc16 mc iTCO_vendor_support mei_pxp mei_hdcp intel_rapl_msr intel_cstate processor_thermal_device_pci_legacy mac80211 snd_pcm_dmaengine i2c_algo_bit spi_nor processor_thermal_device think_lmi libarc4 intel_uncore firmware_attributes_class iwlwifi processor_thermal_rfim mtd ttm pcspkr snd_pcm wmi_bmof processor_thermal_mbox i2c_i801 snd_timer i2c_smbus processor_thermal_rapl intel_ish_ipc drm_display_helper ucsi_acpi snd lenovo_ymc cec intel_lpss_pci soundcore intel_wmi_thunderbolt thunderbolt intel_ishtp mei_me intel_rapl_common cfg80211 typec_ucsi int340x_thermal_zone mei typec intel_lpss intel_gtt vfat idma64 roles intel_soc_dts_iosf i2c_hid_acpi fat i2c_hid ideapad_laptop sparse_keymap platform_profile rfkill soc_button_array int3400_thermal acpi_thermal_rel acpi_pad acpi_tad mac_hid i2c_dev coda sg crypto_user acpi_call(OE) fuse dm_mod loop nfnetlink ip_tables x_tables btrfs blake2b_generic xor raid6_pq libcrc32c crc32c_generic
Jan 02 02:21:24 novo.vcpu kernel: crc32_pclmul crc32c_intel serio_raw sha512_ssse3 atkbd sha256_ssse3 libps2 aesni_intel vivaldi_fmap nvme crypto_simd cryptd nvme_core spi_intel_pci xhci_pci spi_intel nvme_common xhci_pci_renesas video i8042 wmi serio
Jan 02 02:21:24 novo.vcpu kernel: Unloaded tainted modules: nvidia(POE):1
Jan 02 02:21:24 novo.vcpu kernel: CPU: 6 PID: 554890 Comm: btrfs Tainted: P D OE 6.6.8-arch1-1 #1 2ffcc416f976199fcae9446e8159d64f5aa7b1db
Jan 02 02:21:24 novo.vcpu kernel: Hardware name: LENOVO 81Q9/LNVNB161216, BIOS AUCN61WW 04/19/2022
Jan 02 02:21:24 novo.vcpu kernel: RIP: 0010:do_exit+0x8e9/0xb20
Jan 02 02:21:24 novo.vcpu kernel: Code: e9 35 f8 ff ff 48 8b bb 00 06 00 00 31 f6 e8 3e d9 ff ff e9 bd fd ff ff 4c 89 e6 bf 05 06 00 00 e8 0c 1b 01 00 e9 5f f8 ff ff <0f> 0b e9 8e f7 ff ff 0f 0b e9 4b f7 ff ff 48 89 df e8 91 34 12 00
Jan 02 02:21:24 novo.vcpu kernel: RSP: 0000:ffffc9000680bed8 EFLAGS: 00010286
Jan 02 02:21:24 novo.vcpu kernel: RAX: 0000000000000000 RBX: ffff88833e4f2700 RCX: 0000000000000000
Jan 02 02:21:24 novo.vcpu kernel: RDX: 0000000000000001 RSI: 0000000000002710 RDI: ffff888100faf380
Jan 02 02:21:24 novo.vcpu kernel: RBP: ffff88820a0e1680 R08: 0000000000000000 R09: ffffc9000680b580
Jan 02 02:21:24 novo.vcpu kernel: R10: 0000000000000003 R11: ffffffff82eb9850 R12: 000000000000000b
Jan 02 02:21:24 novo.vcpu kernel: R13: ffff888100faf380 R14: ffffc9000680b7a8 R15: ffff88833e4f2700
Jan 02 02:21:24 novo.vcpu kernel: FS: 00007fad5b87a6c0(0000) GS:ffff88848ad80000(0000) knlGS:0000000000000000
Jan 02 02:21:24 novo.vcpu kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
Jan 02 02:21:24 novo.vcpu kernel: CR2: 000055c11731ed60 CR3: 0000000043c4c003 CR4: 0000000000770ee0
Jan 02 02:21:24 novo.vcpu kernel: PKRU: 55555554
Jan 02 02:21:24 novo.vcpu kernel: Call Trace:
Jan 02 02:21:24 novo.vcpu kernel:
Jan 02 02:21:24 novo.vcpu kernel: ? do_exit+0x8e9/0xb20
Jan 02 02:21:24 novo.vcpu kernel: ? __warn+0x81/0x130
Jan 02 02:21:24 novo.vcpu kernel: ? do_exit+0x8e9/0xb20
Jan 02 02:21:24 novo.vcpu kernel: ? report_bug+0x171/0x1a0
Jan 02 02:21:24 novo.vcpu kernel: ? handle_bug+0x3c/0x80
Jan 02 02:21:24 novo.vcpu kernel: ? exc_invalid_op+0x17/0x70
Jan 02 02:21:24 novo.vcpu kernel: ? asm_exc_invalid_op+0x1a/0x20
Jan 02 02:21:24 novo.vcpu kernel: ? do_exit+0x8e9/0xb20
Jan 02 02:21:24 novo.vcpu kernel: ? do_exit+0x70/0xb20
Jan 02 02:21:24 novo.vcpu kernel: ? do_user_addr_fault+0x30f/0x660
Jan 02 02:21:24 novo.vcpu kernel: make_task_dead+0x81/0x170
Jan 02 02:21:24 novo.vcpu kernel: rewind_stack_and_make_dead+0x17/0x20
Jan 02 02:21:24 novo.vcpu kernel: RIP: 0033:0x7fad5b9e33af
Jan 02 02:21:24 novo.vcpu kernel: Code: 00 48 89 44 24 18 31 c0 48 8d 44 24 60 c7 04 24 10 00 00 00 48 89 44 24 08 48 8d 44 24 20 48 89 44 24 10 b8 10 00 00 00 0f 05 <89> c2 3d 00 f0 ff ff 77 18 48 8b 44 24 18 64 48 2b 04 25 28 00 00
Jan 02 02:21:24 novo.vcpu kernel: RSP: 002b:00007fad5b879c80 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
Jan 02 02:21:24 novo.vcpu kernel: RAX: ffffffffffffffda RBX: 0000562c0a109450 RCX: 00007fad5b9e33af
Jan 02 02:21:24 novo.vcpu kernel: RDX: 0000562c0a109450 RSI: 00000000c400941b RDI: 0000000000000003
Jan 02 02:21:24 novo.vcpu kernel: RBP: 0000000000000000 R08: 00007fad5b87a6c0 R09: 0000000000000000
Jan 02 02:21:24 novo.vcpu kernel: R10: 0000000000000000 R11: 0000000000000246 R12: fffffffffffffdb8
Jan 02 02:21:24 novo.vcpu kernel: R13: 0000000000000000 R14: 00007ffe13568550 R15: 00007fad5b07a000
Jan 02 02:21:24 novo.vcpu kernel:
Jan 02 02:21:24 novo.vcpu kernel: ---[ end trace 0000000000000000 ]---
Jan 02 02:21:24 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 10910683136 length 4096
Jan 02 02:21:24 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 10910683136 length 4096
Jan 02 02:21:24 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 10910687232 length 4096
Jan 02 02:21:24 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 10910687232 length 4096
Jan 02 02:21:24 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 10910691328 length 4096
Jan 02 02:21:24 novo.vcpu kernel: BTRFS critical (device nvme0n1p4): unable to find chunk map for logical 10910691328 length 4096