18
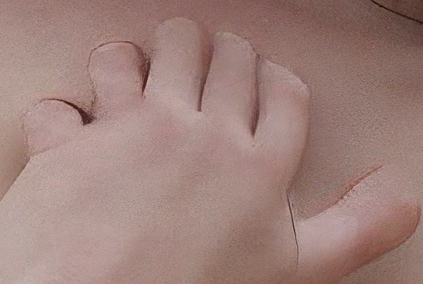
"I can just use a depth map to get perfect hands!" he said...
(lemmy.dbzer0.com)
There are sometimes days where the gods of SD are just mocking you. That hand was made from a depth map extracted from a real human pose, and the map very clearly show FOUR FUCKING FINGERS. And yet...
I am starting to wonder if this model was trained exclusively on people with polydactyly. If so, well played internet.
I have tried a bunch of stuff to get good hands and feet from SD, and nothing is even slightly reliable. TI and negative prompts sometimes just don't work, or even make stuff worse. Inpainting takes forever to make work well. I thought controlnet would crack it but apparently not.
How do you guys deal with dodecadactyl mutants?
A lot of the time I try to just let images come out as the AI imagines them - Just running img2img prompts, often in big batches, then picking the pictures that best reflect what I wanted.
But I do also have another process when I want something specific, which involves doing img2img to generate a pose and general composition, flipping that image into both a controlnet (for composition) and a segmentanything mask (for latent couple) and then respinning the same image with the same seed with those new constraints. When you run with the controlnet and the mask you can turn the CFG way down (3 or 4) but keep the coherence in the image so you get much more naturalistic outputs.
This is also a good way to work with LORAs that are either poorly made or don't work well together - The initial output might look really burned, but when you have the composition locked in you can run the LORAs at much lower strength and with lower CFG so they sit together better.