46
[2024 Day 5] Three characters difference
(programming.dev)
I don't remember exactly what this difference caused but I do remember it being very annoying to debug.
Edit: the language used is Uiua
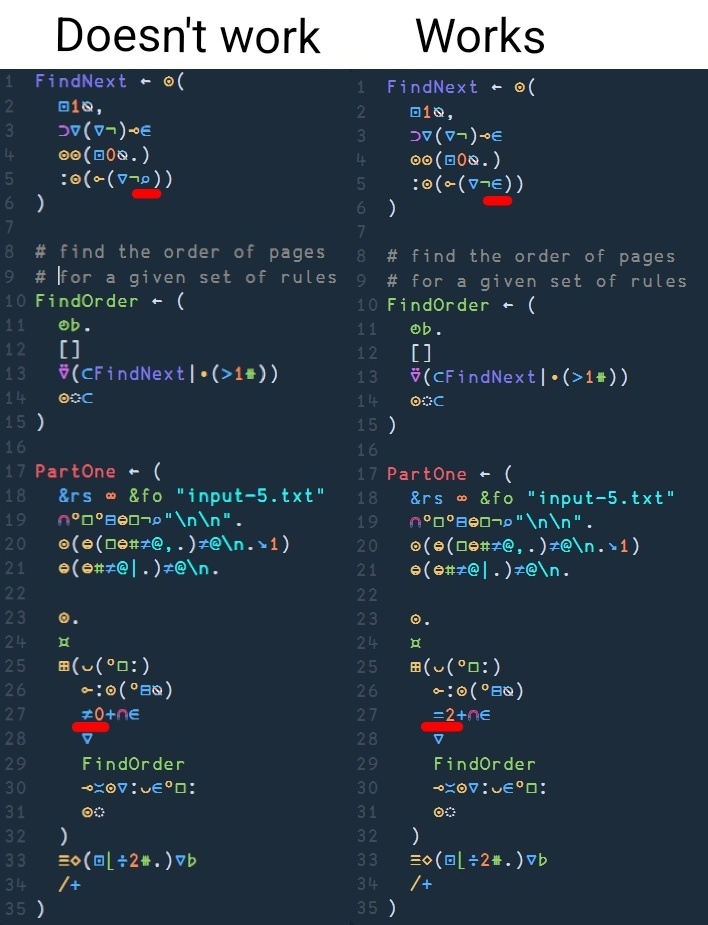
Welp, got frustrated again with part one because there kept being something wrong with my totally-not-ugly loop and so came here again. I did have to change
IsInt(and thus alsoCostto account for different handling) for part two though because I kept getting wrong results for my input.I'm guessing it's because uiua didn't see the difference between rounded and non-rounded number anymore.
Here's the updated, slightly messier version of the two functions that worked out for me in the end :D
~Could~ ~have~ ~been~ ~done~ ~better~ ~but~ ~I'm~ ~lacking~ ~the~ ~patience~ ~for~ ~that~ ~now~