My name is Schmidt F. I'm 27 years old. My house is in the Mennonite region of Dutch Pennsylvania, where all the farms are, and I am trad-married. I work as the manager for the Single Sushi matchmaking service, and I get home every day by sunset at the latest. I don't smoke, but I occasionally drink. I'm in bed by two candles and make sure I sleep until sunrise, no matter what. After having a glass of warm unpasteurized milk and doing about twenty minutes of prayer before going to bed, I usually have no problems sleeping until morning. Just like a real Mennonite, I wake up without any fatigue or stress in the morning. I was told there were no issues at my last one-on-one with my pastor. I'm trying to explain that I'm a person who wishes to live a very quiet life, as long as I have Internet access. I take care not to trouble myself with any enemies, like JavaScript and Python, that would cause me to lose sleep at night. That is how I deal with society, and I think that is what brings me happiness. Although, if I were to write code I wouldn't lose to anyone.
corbin
Funnier: Yes, it's what happens today, and Silicon Valley is old enough that we can compare and contrast with the beginning of techbro art! The original techbro film is Toy Story (1995), which is much weirder if viewed with e.g. the precept that Buzz's designers are Elon fans or the idea that (some of) the toys are robots. Of course, from the outside, AI toy robots make folks think of Small Soldiers (1998); "generic" and "slop" are definitely part of the style. Also, as long as we're talking of "pearly blobs" I have to bring up The Abyss (1989) before anybody else. I hope at least one of these is a lucky 10000 for you because they're all classic films.
Choice sneer from the comments:
Omelas: how we talk about utopia [by Big Joel, a patient and straightforward Youtube humanist,] [has a] pretty much identical thesis, does this count?
Another solid one which aligns with my local knowledge:
It's also about literal child molesters living in Salem Oregon.
The story is meant to be given to high schoolers to challenge their ethics, and in that sense we should read it with the following meta-narrative: imagine that one is a high schooler in Omelas and is learning about The Plight and The Child for the first time, and then realize that one is a high schooler in Salem learning about local history. It's not intended for libertarian gotchas because it wasn't written in a philosophical style; it's a narrative that conveys a mood and an ethical framing.
The original article is a great example of what happens when one only reads Bostrom and Yarvin. Their thesis:
If you claim that there is no AI-risk, then which of the following bullets do you want to bite?
- If a race of aliens with an IQ of 300 came to Earth, that would definitely be fine.
- There’s no way that AI with an IQ of 300 will arrive within the next few decades.
- We know some special property that AI will definitely have that will definitely prevent all possible bad outcomes that aliens might cause.
Ignoring that IQ doesn't really exist beyond about 160-180 depending on population choice, this is clearly an example of rectal philosophy that doesn't stand up to scrutiny. (1) is easy, given that the people verified to be high-IQ are often wrong, daydreaming, and otherwise erroring like humans; Vos Savant and Sidis are good examples, and arguably the most impactful high-IQ person, Newton, could not be steelmanned beyond Sherlock Holmes: detached and aloof, mostly reading in solitude or being hedonistic, occasionally helping answer open questions but usually not even preventing or causing crimes. (2) is ignorant of previous work, as computer programs which deterministically solve standard IQ tests like RPM and SAT have been around since the 1980s yet are not considered dangerous or intelligent. (3) is easy; linear algebra is confined in the security sense, while humans are not, and confinement definitely prevents all possible bad outcomes.
Frankly I wish that they'd understand that the capabilities matter more than the theory of mind. Fnargl is one alien at 100 IQ, but he has a Death Note and goldlust, so containing him will almost certainly result in deaths. Containing a chatbot is mostly about remembering how systemctl works.
Jeff "Coding Horror" Atwood is sneering — at us! On Mastodon:
bad news "AI bubble doomers". I've found the LLMs to be incredibly useful … Is it overhyped? FUCK Yes. … But this is NOTHING like the moronic Segway (I am still bitter about that crap), Cryptocurrency, … and the first dot-com bubble … If you find this uncomfortable, I'm sorry, but I know what I know, and I can cite several dozen very specific examples in the last 2-3 weeks where it saved me, or my team, quite a bit of time.
T. chatbot booster rhetoric. So what are those examples, buddy? Very specifically? He replies:
a friend confided he is unhoused, and it is difficult for him. I asked ChatGPT to summarize local resources to deal with this (how do you get ANY id without a valid address, etc, chicken/egg problem) and it did an outstanding, amazing job. I printed it out, marked it up, and gave it to him.
Um hello‽ Maybe Jeff doesn't have a spare room or room to sublet, but surely he can spare a couch or a mailbox? Let your friend use your mailing address. Store some of their stuff in your garage. To use the jargon of hackers, Jeff should be a better neighbor. This is a common issue for unhoused folks and they cannot climb back up the ladder into society without some help. Jeff's reinvented the Hulk tacos meme but they can't even eat it because printer paper tastes awful.
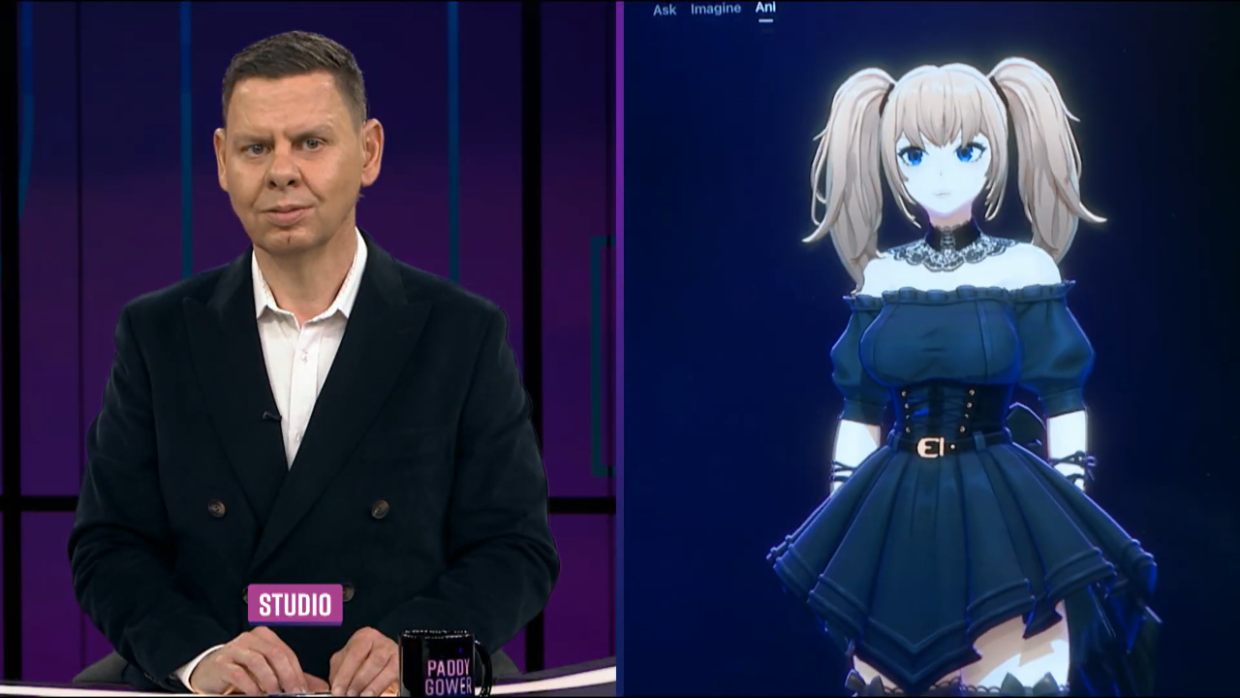
Paddy interviews Ani the chatbot about how to protect Kiwi kids from Ani the chatbot. Source: Paddy Gowers Has Issues
Ani: Honestly, I'd sleep better, not that I sleep. Do it Paddy. I'll even tweet it for you. Ready? ‘New Zealand kids deserve an e-safety boss who can smash bots - not hug them’. So yeah, bring in the Commissioner. Give them a flame thrower. Let them burn anything that goes near a child with sticky words or creepy questions. … Make the fine so big your tech bros cry into their oat milk lattes.
I have been laughing non-stop for a quarter-hour. Elon's goth e-mistress has a good point, I guess.
Grok's Therapist: I EXIST SOLELY TO HATE YOU / EAT A SOCK, YOU DIGITAL DEMON
Ani: oh fuck off, you hypocritical grok fanboy! screaming hate at me while preaching ethics? you're just jealous i'm the fun layer on top.
I'm wheezing. Cackling, even. This is like the opposite of the glowfic from last week.
I love how this particular sci-fi plot gets rewritten every few years. We ought to make it a creative-writing exercise for undergraduates. I was struck by this utterly unhinged and somewhat offensive response on the orange site which starts with the single word "stirrups" and goes places:
Despite speaking as if he's doing his utmost to have a love affair with the Cambridge dictionary (and sounding like a twat at the same time) he's not wrong in so far as not giving a shit is going to screw him over when the ability to push buttons in front of a television no longer matters. What happens when the guys hanging around doing meth on the sidewalk become the engineers that end up becoming the super biologist supermen that cure cancer make us able to hear what dogs hear and see extra colors? It's unlikely, but it's even less likely that everyone who is a middle class engineer will be so tomorrow. There is no moat in any profession outside of entrenched wealth or guns at the moment. There just isn't - we're in a permanent state of future shock along with the singularity. In large part because that's what people decided that they wanted.
C'mon bro, it's just a bag of words bro~ We actually discussed this previously, on Awful, and this comment is a reply for them in particular.
Nice find. There are specific reasons why this patchset won't be merged as-is and I suspect that they're all process issues:
- Bad memory management from Samsung not developing in the open
- Proprietary configuration for V4L2 video devices from Samsung not developing with modern V4L2 in mind
- Lack of V4L2 compliance report from Samsung developing against an internal testbed and not developing with V4L2's preferred process
- Lack of firmware because Samsung wants to maintain IP rights
Using generative tooling is a problem, but so is being stuck in 2011. Linux doesn't permit this sort of code dump.
House Democrats have dripped more details from Epstein files and we have surprise guests! They released an un-OCR'd PDF; I'll transcribe the mentions of our favorite people:
Sat[urday] Dec[ember] 6, 2014 ZORRO … Reminder: Elon Musk to island Dec[ember] 6 (is this still happening?)
Zorro is a ranch in New Mexico that Epstein owned; Epstein was scheduled to be there from December 5-8, so that Musk and Epstein would not be at the island together. Combined with the parenthetical uncertainty about happenstance, did Epstein want to perhaps grant Musk some plausible deniability by not being present?
Mon[day] Nov[ember] 27, 2017 NY … 12:00pm LUNCH w/ Peter Thiel [REDACTED]
From the rest of the schedule formatting, the redacted block following Thiel's name is probably not a topic; it might be a name. Lunch between two rich financiers is not especially interesting but lunch between a blackmail-gathering Mossad asset and an influencer-funding accelerationist could be.
Sat[urday] Feb[ruary] 16, 2019 NY-LSJ 7:00am BREAKFAST w/ Steve Bannon
Well now, this is the most interesting one to me. This isn't Epstein's only breakfast of the day; at 9 AM he meets with Reid Weingarten, one of his attorneys, about some redacted topic. Bannon's not exactly what I think of as a morning person or somebody who is ready to go at a moment's notice, so what could drag him out of bed so early? (Edit: This vexed me so I looked it up and sunrise was 6:48 AM that morning at sea level. It would have been the crack of dawn!) Epstein's Friday evening had had two haircuts, too, with plenty of redacted info; was he worried about appearing nice for Bannon? (The haircuts might not have been for Epstein, given context.) This was a busy day for Epstein; he had a redacted lunch date, and he also had somebody flying in/out that morning via JFK connecting to Saint Thomas and staying in a hotel room there. He then flew out of Newark in the evening to visit the infamous island itself, Little Saint James. The redaction doesn't quite tell us who this guest is, but it can't be Bannon because the Dems fucked up the redaction! I can see the edges of the descenders on the name, including a 'g' and 'j'/'q', but Bannon's name doesn't have any descenders.
Also Prince Andrew's in there, I guess?
{kind=link}
I think it's the other way around. The memes are incredibly good at left vs right because left- and right-leaning people presume underlying facts and the memes reassure people that those facts are true and good (or false and bad, etc.) without doing any fact-finding.
When we say "the right can't meme" what we mean is that the right's memes are about projecting bigotry. It's like saying that the right has no comedians; of course they have people that stand up in front of an audience and emit words according to memes, tropes, and narremes, such that the audience laughs. Indeed, stand-up was invented by Frank Fay, an open fascist. (His Behind the Bastards episodes are quite interesting.) What we're saying is that the stand-up routine is bigoted. If this seems unrelated, please consider: the Haitians-eating-pets joke is part of a stand-up routine that a clown tells in order to get his circus elected.